
SUM FIELDS JCL: Record Summation and Duplicate Elimination
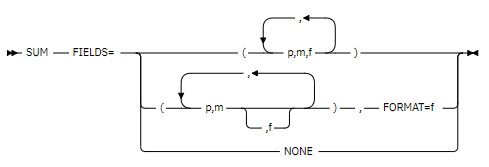
The SUM FIELDS JCL statement indicates that when two records have equal control fields in a SORT or merge operation, the summary fields are summed, the sum is placed in one of the records, and the other is deleted. If the EQUALS option is activated, the first record is retained; if the NOEQUALS option is activated, the retained record is unpredictable.
SUM FIELDS JCL: Example of Command Usage
Here is an example of SUM FIELDS JCL where the program sorts records by customer ID, sums the sales for each customer, and eliminates duplicates. The result is an output file with a single record per customer, displaying the total sum of their sales.
//SORTJOB JOB ...
//STEP1 EXEC PGM=SORT
//SYSOUT DD SYSOUT=*
//SORTIN DD DSN=input.dataset,DISP=SHR
//SORTOUT DD DSN=output.dataset,DISP=(NEW,CATLG,DELETE),
// UNIT=SYSDA,SPACE=(CYL,(5,5)),DCB=(RECFM=FB,LRECL=80)
//SYSIN DD *
SORT FIELDS=(1,3,CH,A)
SUM FIELDS=(10,3,ZD),FORMAT=BI
/*Input Data: The program takes as input a data file named input.dataset. This file contains sales information, with columns for customer ID, first name, last name, and sales amount.
Sorting: The first step of the program is to sort the records in the input file by customer ID (ID) in ascending order. This is done using the statement SORT FIELDS=(1,3,CH,A), which specifies that records should be sorted based on the first 3 characters (the ID column) as the sorting key.
Field Summation: Next, the program uses the statement SUM FIELDS=(10,3,ZD),FORMAT=BI to sum the values in the Sales column for each customer ID. The part (10,3,ZD) indicates that the program will sum the field from position 10 to 12 in each record, which represents the sales amount, and FORMAT=BI specifies that these values should be treated as unsigned binary integers.
Output Data: The final result is written to a file named output.dataset, which contains unique records with the accumulated sum in the Sales column for each customer ID.
Input file (input.dataset):
ID NAME SURNAME SALES
-----------------------------------
001 JOHN SMITH 100
002 MARY JOHNSON 150
001 JOHN SMITH 200
003 CHARLES DAVIS 300
002 MARY JOHNSON 250Result after processing (output.dataset):
ID NAME SURNAME SALES
-----------------------------------
001 JOHN SMITH 300
002 MARY JOHNSON 400
003 CHARLES DAVIS 300Summary Field Formats and Lengths in SUM FIELDS JCL
| Summary Field Format Code | Length | Description |
| BI | 2, 4, or 8 bytes | Unsigned binary |
| FI | 2, 4, or 8 bytes | Signed fixed-point |
| FL | 4, 8, or 16 bytes | Signed hexadecimal floating-point |
| PD | 1 to 16 bytes | Signed packed decimal |
| ZD | 1 to 31 bytes | Signed zoned decimal |
SUM FIELDS NONE: Duplicate Control
The SUM FIELDS NONE command in JCL is used to eliminate duplicate records based on a specified sorting key during the data sorting and summarization operation. When using SUM FIELDS NONE, the system retains only a single record for each unique value of the sorting key, thereby eliminating duplicate records.
Example of SUM FIELDS NONE
Here is a simplified example of how to use SUM FIELDS NONE in JCL to remove duplicate records based on a sorting key:
Suppose you have an input file named input.dataset with the following structure:
Input File
ID NAME SURNAME
--------------------------
001 JOHN SMITH
002 MARY JOHNSON
001 JOHN SMITH
003 CHARLES DAVIS
002 MARY JOHNSONAnd you want to eliminate duplicate records based on the “ID” field. You can use SUM FIELDS NONE to achieve this in your JCL:
//SORTJOB JOB …
//STEP1 EXEC PGM=SORT
//SYSOUT DD SYSOUT=*
//SORTIN DD DSN=input.dataset,DISP=SHR
//SORTOUT DD DSN=output.dataset,DISP=(NEW,CATLG,DELETE),
// UNIT=SYSDA,SPACE=(CYL,(5,5)),DCB=(RECFM=FB,LRECL=80)
//SYSIN DD *
SORT FIELDS=(1,3,CH,A)
SUM FIELDS=NONE
/*After executing this JCL, the output file output.dataset will contain only the unique records based on the “ID” field:
Output File
ID NAME SURNAME
--------------------------
001 JOHN SMITH
002 MARY JOHNSON
003 CHARLES DAVISAs shown in the example, duplicate records based on the “ID” field have been eliminated, keeping only one instance of each unique value of the sorting key. This simplifies and reduces redundancy in the output dataset.