
SUM FIELDS JCL: Suma de Registros y Eliminación de duplicados
El control de declaración SUM FIELDS JCL, indica que cuando dos registros tienen campos de control de un SORT o fusión iguales, se suman los campos de resumen, se coloca la suma en uno de los registros y se elimina el otro. Si está activada la opción EQUALS, se conserva el primer registro; si está activada la opción NOEQUALS, el registro conservado es impredecible.
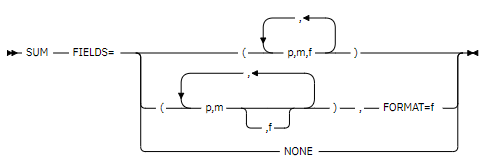
SUM FIELDS JCL: Ejemplo de uso del comando
A continuación se muestra un ejemplo de SUM FIELDS JCL donde el programa ordena los registros por ID de cliente, suma las ventas para cada cliente y elimina los duplicados. El resultado es un archivo de salida con un único registro por cliente, mostrando la suma total de sus ventas.
//SORTJOB JOB ...
//STEP1 EXEC PGM=SORT
//SYSOUT DD SYSOUT=*
//SORTIN DD DSN=input.dataset,DISP=SHR
//SORTOUT DD DSN=output.dataset,DISP=(NEW,CATLG,DELETE),
// UNIT=SYSDA,SPACE=(CYL,(5,5)),DCB=(RECFM=FB,LRECL=80)
//SYSIN DD *
SORT FIELDS=(1,3,CH,A)
SUM FIELDS=(10,3,ZD),FORMAT=BI
/*
Entrada de datos: El programa toma como entrada un archivo de datos llamado input.dataset. Este archivo contiene información sobre ventas, con columnas para el ID del cliente, el nombre, el apellido y la cantidad de ventas.
Ordenación: El primer paso del programa es ordenar los registros del archivo de entrada por el ID del cliente (ID) de manera ascendente. Esto se realiza utilizando la instrucción SORT FIELDS=(1,3,CH,A), que especifica que los registros deben ordenarse utilizando los primeros 3 caracteres (la columna ID) como clave de ordenación.
Suma de campos: Luego, el programa utiliza la instrucción SUM FIELDS=(10,3,ZD),FORMAT=BI para sumar los valores de la columna Ventas para cada ID de cliente. La parte (10,3,ZD) indica que se sumará el campo de la posición 10 al 12 del registro, que representa las ventas, y FORMAT=BI especifica que estos valores deben tratarse como enteros binarios sin signo.
Salida de datos: El resultado final se escribe en un archivo llamado output.dataset, que contiene los registros únicos con la suma acumulada en la columna Ventas para cada ID de cliente.
Archivo de entrada (input.dataset):
ID Nombre Apellido Ventas
------------------------------------
001 Juan Pérez 100
002 María López 150
001 Juan Pérez 200
003 Carlos García 300
002 María López 250
Resultado después del procesamiento (output.dataset):
ID Nombre Apellido Ventas
------------------------------------
001 Juan Pérez 300
002 María López 400
003 Carlos García 300
Formatos y Longitudes de Campos de Resumen de SUM FIELDS JCL
| Código de Formato de Campos de Resumen | Longitud | Descripción |
| BI | 2, 4, o 8 bytes | Binario no signado |
| FI | 2, 4, o 8 bytes | Punto fijo con signo |
| FL | 4, 8, o 16 bytes | Punto flotante hexadecimal con signo |
| PD | 1 a 16 bytes | Decimal empaquetado con signo |
| ZD | 1 a 31 bytes | Decimal zonal con signo |
SUM FIELDS NONE: Control de duplicados
El comando SUM FIELDS NONE en JCL se utiliza para eliminar registros duplicados basados en una clave de ordenación especificada durante la operación de ordenación y resumen de datos. Cuando se utiliza SUM FIELDS NONE, el sistema solo retiene un único registro para cada valor único de la clave de ordenación, eliminando así los registros duplicados.
Ejemplo de SUM FIELDS NONE
A continuación se muestra un ejemplo simplificado de cómo usar SUM FIELDS NONE en un control de JCL para eliminar registros duplicados basados en una clave de ordenación:
Supongamos que tienes un archivo de entrada llamado input.dataset con la siguiente estructura:
Fichero de entrada
ID Nombre Apellido
----------------------------
001 Juan Pérez
002 María López
001 Juan Pérez
003 Carlos García
002 María López
Y se quieren eliminar los registros duplicados basados en el campo «ID». Puedes usar SUM FIELDS NONE para lograr esto en tu JCL:
//SORTJOB JOB …
//STEP1 EXEC PGM=SORT
//SYSOUT DD SYSOUT=*
//SORTIN DD DSN=input.dataset,DISP=SHR
//SORTOUT DD DSN=output.dataset,DISP=(NEW,CATLG,DELETE),
// UNIT=SYSDA,SPACE=(CYL,(5,5)),DCB=(RECFM=FB,LRECL=80)
//SYSIN DD *
SORT FIELDS=(1,3,CH,A)
SUM FIELDS=NONE
/*Después de ejecutar este JCL, el archivo de salida output.dataset contendrá solo los registros únicos basados en el campo «ID»:
Fichero de salida
ID Nombre Apellido
----------------------------
001 Juan Pérez
002 María López
003 Carlos García
Como se muestra en el ejemplo, los registros duplicados basados en el campo «ID» se han eliminado, manteniendo solo una instancia de cada valor único de la clave de ordenación. Esto simplifica y reduce la redundancia en el conjunto de datos de salida.
JCL: Cómo Ejecutar un Proceso


Este libro explora el Job Control Language (JCL), esencial para ejecutar procesos en sistemas mainframe. Aprender JCL es fundamental para optimizar y automatizar tareas en sistemas IBM, y esta guía te muestra cómo hacerlo de manera práctica y efectiva.
Temas principales
- Estructura y comandos esenciales de JCL
- Creación y gestión de trabajos
- Optimización de recursos y manejo de errores
- Ejemplos prácticos de configuración de procesos
Con esta lectura, podrás mejorar la eficiencia de tus trabajos en mainframe, aumentando tu productividad en proyectos complejos.